


- Details
- KI
Wenn KI von KI lernt, wird die Welt kleiner
Eine neue Studie warnt vor dem sogenannten Model Collapse: Werden künftige KI-Systeme vor allem mit KI-generierten Inhalten trainiert, verlieren sie schrittweise den Kontakt zur Vielfalt der realen Welt. Für Unternehmen wird damit eine Ressource noch wertvoller: verlässliche, menschlich erzeugte Daten.
Es klingt zunächst wie ein akademisches Randproblem, ist aber ziemlich nah am Maschinenraum der digitalen Wirtschaft: Was passiert, wenn KI-Systeme nicht mehr vor allem aus Texten, Bildern und Daten lernen, die Menschen erzeugt haben, sondern aus Material, das andere KI-Systeme produziert haben? Die Antwort einer Studie von Forschern aus Oxford, Cambridge, Imperial College London, Toronto und dem Vector Institute ist wenig beruhigend: Die Modelle beginnen zu vergessen.
Die Arbeit trägt den treffenden Titel „The Curse of Recursion: Training on Generated Data Makes Models Forget“. Gemeint ist ein Rückkopplungseffekt. Ein Modell wird auf menschlichen Daten trainiert, erzeugt neue Inhalte, diese landen wieder im Netz, werden später von der nächsten Modellgeneration eingesammelt und dienen dort als Trainingsmaterial. Was wie eine effiziente Recyclingmaschine aussieht, kann zu einer intellektuellen Verarmung führen.
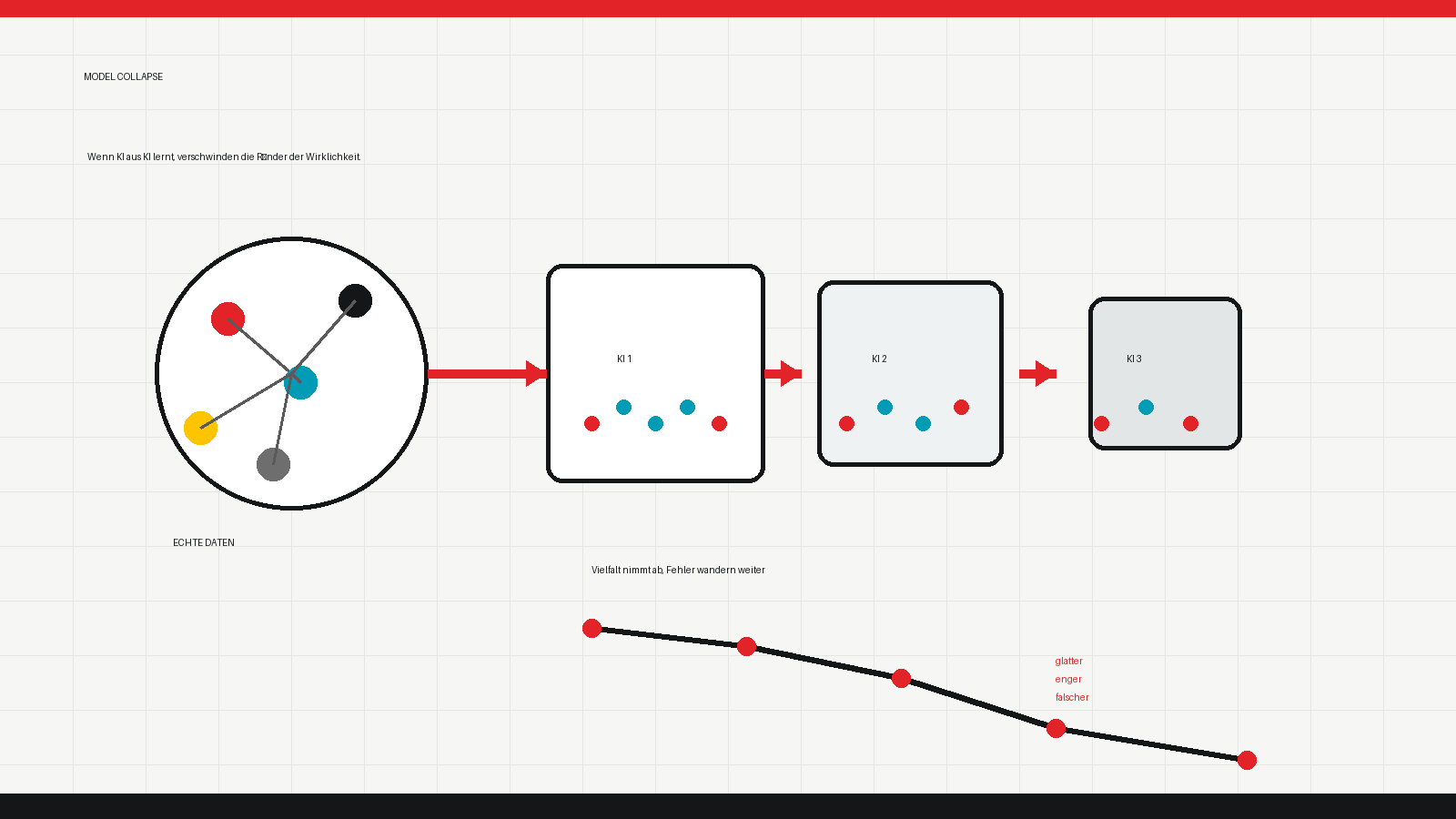
Die Autoren nennen den Prozess „Model Collapse“. Er beschreibt, dass generative Modelle über mehrere Generationen hinweg die ursprüngliche Datenverteilung falsch wahrnehmen. Zuerst verschwinden die Ränder: seltene Ereignisse, ungewöhnliche Formulierungen, Minderheitenperspektiven, Ausnahmen. Später können sich unterschiedliche Muster vermischen, bis das Modell eine glattere, engere und letztlich weniger realistische Version der Welt produziert.
Das ist mehr als ein technisches Detail. Viele Geschäftsmodelle rund um generative KI hängen daran, dass das offene Web als Trainingsquelle verfügbar bleibt. Doch je mehr synthetischer Content dort zirkuliert, desto schwieriger wird es, die Herkunft von Daten zu unterscheiden. Das Netz wird dann nicht automatisch klüger, sondern möglicherweise selbstreferenzieller: Modelle lernen von Modellen, Fehler werden weitergereicht, Wahrscheinlichkeiten verstärkt, Abweichungen abgeschliffen.
Die Studie zeigt den Effekt nicht nur theoretisch, sondern an mehreren Modelltypen: Gaussian Mixture Models, Variational Autoencoders und Sprachmodelle. Bei Sprachmodellen untersuchten die Forscher unter anderem feinjustierte OPT-125m-Modelle auf Basis von Wikitext2. Das Ergebnis: Auch wenn die Modelle weiterhin Teile der Aufgabe lernen, verschlechtert sich die Leistung über Generationen. Wird ein Anteil echter Originaldaten erhalten, fällt die Degradation geringer aus. Menschliche Daten wirken also wie ein Gegengift gegen den Rückkopplungsschaden.
Die Mechanik dahinter ist nüchtern. Erstens gibt es statistische Fehler: Kein Datensatz bildet die Welt vollständig ab, und bei jeder Stichprobe kann Information verloren gehen. Zweitens gibt es Modellfehler: Kein Modell bildet die Realität perfekt ab. Werden diese kleinen Abweichungen wieder und wieder als neue Realität behandelt, wachsen sie sich aus. Das Modell vergisst nicht wie ein Mensch. Es verengt sein Bild davon, was überhaupt wahrscheinlich, relevant oder normal ist.
Besonders brisant ist der Verlust der seltenen Fälle. In der Wirtschaft sind genau diese Randlagen oft entscheidend: außergewöhnliche Kundenbedürfnisse, Sonderfälle in der Produktion, Sicherheitsvorfälle, Betrugsversuche, regulatorische Ausnahmen, regionale Besonderheiten. Wer nur noch den statistischen Durchschnitt sieht, optimiert am echten Problem vorbei. Für Fairnessfragen ist das ebenso heikel, weil marginalisierte Gruppen in Daten oft ohnehin unterrepräsentiert sind.
Für Unternehmen hat die Studie eine klare Botschaft: Datenprovenienz wird zur strategischen Disziplin. Es reicht nicht, möglichst viel Content einzusammeln. Entscheidend wird, zu wissen, woher Daten stammen, ob sie menschlich erzeugt, synthetisch erweitert oder vollständig KI-generiert sind und welche Qualitätssicherung dahintersteht. Wer über eigene, saubere, reale Interaktionsdaten verfügt, besitzt in einer synthetisch überfluteten Informationswelt einen Wettbewerbsvorteil.
Das verändert auch die Debatte über KI-Governance. Wasserzeichen, Herkunftsnachweise, Content-Kennzeichnung und Datentreuhandmodelle sind nicht nur medienpolitische Spielereien. Sie könnten Voraussetzung dafür werden, dass die nächste Modellgeneration nicht im eigenen Echo trainiert. Die Autoren sprechen explizit von der Notwendigkeit, Zugang zu ursprünglichen Datenquellen zu bewahren und zusätzliche nicht von LLMs erzeugte Daten verfügbar zu halten.
Für Medien ist die Pointe fast unangenehm naheliegend. Wenn menschlich recherchierte, geprüfte und kontextualisierte Inhalte knapper werden, steigt ihr Wert. Nicht, weil KI unnütz wäre. Sondern weil KI ohne verlässliche Wirklichkeitszufuhr ihre eigene Plastikwelt baut. Der Journalismus, die Wissenschaft, die Verwaltung, Unternehmen mit echten Prozessdaten: Sie alle liefern jene Reibung, die Modelle brauchen, um nicht nur flüssig, sondern richtig zu bleiben.
Der Hype um generative KI hat lange so geklungen, als sei Datenmenge die entscheidende Währung. Die Studie verschiebt den Akzent. Menge allein genügt nicht, wenn die Daten ihre Herkunft verlieren. Qualität, Vielfalt, Nachweisbarkeit und menschliche Originalität werden zu Infrastrukturfragen. Das ist weniger glamourös als die nächste Modellpräsentation, aber vermutlich wichtiger.
Am Ende ist Model Collapse eine Warnung vor digitaler Inzucht. Wenn künstliche Intelligenz vor allem aus künstlicher Intelligenz lernt, wird sie nicht automatisch künstlich klüger. Sie wird zunächst glatter, dann enger und irgendwann falsch. Die Zukunft der KI hängt deshalb nicht nur von größeren Rechenzentren ab. Sie hängt auch daran, ob wir genug echte Welt in den Trainingsdaten bewahren.
Basis: Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson: „The Curse of Recursion: Training on Generated Data Makes Models Forget“, arXiv:2305.17493v3, 14. April 2024.
- Details
Leben & StilView all
- Details
- Köpfe
Das Jobkarussell dreht sich im Juli 2026
- Redaktion
- 24.Juli.2026
- Details
- Köpfe

Aon: Michael Sturmlechner ist neuer CEO
- Redaktion
- 20.Juli.2026
- Details
- Köpfe

Vorstandswechsel bei der Open Fiber Austria
- Redaktion
- 19.Juli.2026
- Details
- Leben & Stil

Inhaltlich gestellt
- Rainer Sigl
- 17.Juli.2026
Office & TalkView all
- Details
- Officetalk

Österreichs größte Baureserve steht leer
- Gerhard Popp
- 13.Juli.2026
- Details
- Officetalk

Datenkapital mit Seeblick: die erste Summer Edition der Bau Invest Lounge
- Bernd Affenzeller
- 06.Juli.2026
- Details
- Officetalk

Vier Blicke auf den Bestand: Wie die Zukunft des Bauens aussieht
- Gerhard Popp
- 03.Juli.2026
- Details
- Officetalk

Tragen durch Form: Das Siegerprojekt der Concrete Design Competition
- Bernd Affenzeller
- 02.Juli.2026
Produkte & ProjekteView all
- Details
- Produkte & Projekte

Kühle Nächte, angenehme Räume
- Redaktion
- 21.Juli.2026
- Details
- Projekte

Primetals: Brownfield-Conversion auf SAP S/4HANA
- Redaktion
- 20.Juli.2026
- Details
- Produkte & Projekte

Strom für die schweren Aufgaben
- Alina Flatscher
- 14.Juli.2026
- Details
- Produkte & Projekte

Viermal ÖGNI-Gold für PIER05
- Redaktion
- 13.Juli.2026